华为电信软件平台中间件大数据平台高级经理谢国强分享了华为大数据领域实施的多维分析的探索。 据了解从09年开始,华为是Hadoop社区的参与者,目前华为是在电信行业唯一在Apache基金银牌赞助商,伴随着Hadoop2.0发布了之后高可用性在社区里讨论的非常热烈。而像基于hadoop的大数据平台的已经作为华为的基础的平台。
华为大数据的创新,基于Hadoop上的数据挖掘、内存分析、ETL和优化ETL支撑上层解决方案领域上做很多尝试。Hadoop可以看到相关的很多东西,过去Hadoop的分析能力基本广泛把应用在批量的非实时的处理上,一直以来大家都在尝试分析的性能提升,快速的分析到Hadoop上的数据。说到底Hadoop还是一个数据处理系统,回到数据处理的本质上看,有很巨大的性能瓶颈,如何提高CPU计算效率,内存分析计等都成为解决问题的方向。
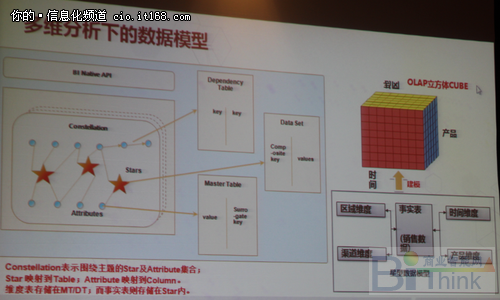
谢国强介绍了多维分析的数据模型,实时表关联多个维表非常庞大,维表数据相对会比较小一些。新型模型的数据模型把所有的尾表编码到数据代码里去,建了分布式的智能索引,运用了R树索引技术,但是R树个缺点,所以华为将R树索引上做了一个二级索引,采用B树和R树互相补充的方式,主节点上的R树上存储了子节点上的所有的B树索引的范围,R树全部放在内存上,可以快速的通过维度信息范围,快速定位到子节点上的索引上去,这种索引的方式,索引重点是解决IO的问题,能够快速的找到我们所需要的数据。
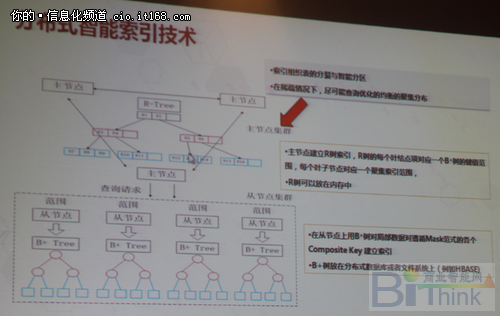
二层分布式的智能索引和传统的索引做了简单的对比,在可扩展性、适用范围、占用的空间、使用的透明和统一信息上,分布式索引有绝对的优势,由于把所有的维度信息都编码到我们的索引空间里去了,它不像传统的DMS的数据库系统一样,先有一张表,在这表上建索引。所有的索引集数据的方式,找到了索引也找到了这个数据。

此外还要面临存储的IO的问题,如何再进一步把IO降下来,比如说HBase里存储的时候把索引这部分和值的部分做了分离,维度信息相对而言还是比较少的。而分布式的问题,所有的节点都在参与运算,华为则对数据编码进行了智能的算法,尽可能的分布提高了并行度,同时做了Key,大量的减少IO,如果数据是稀疏的话性能提升至少是2到5倍,因为跳过了大量的数据访问。

美国专家做的专利的技术,grasshopper,在空间曲线里到底下一个数据在哪?这是我们要解决的问题,首先说会有三种方式,因为数据是没有排序,海量数据做排序是很难的,三种方式,一种是顺序扫描,一种是随机跳,第三种是尽可能的跳到我要找到的数据附近,并且找到它。这里要引入我们的优化策略,我们不断的在摄取数据的同时,会根据摄取的成本优化我们的跳跃找数据的方法。
通过Grasshopper算法的性能优化,和“爆扫”数据做了对比,整体上在任何的情况下都会比爆扫要优,我们还有“随机跳”,因为它可比性很有趣,运气很好可能一下就跳到了,但是也有可能永远都跳不到。
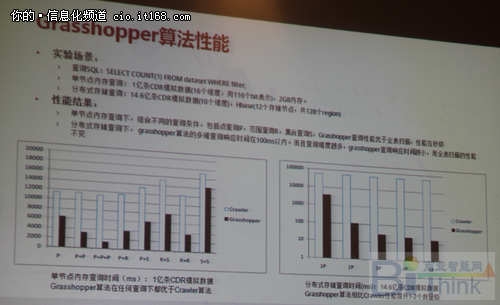
通过算法优化的,与传统系统做对比,谢国强认为可能不太公平但是效果是显而易见的,120亿条,5TB的数据通过多维分析索引的技术,做了26维度,大概每秒700万左右记录产生的情况,此外通过分组上的测试,通过不同的维度以及相同的分组的情况,整体上的性能都在10秒以内
在现场我们不仅看到了华为在大数据方向的努力和尝试,更看到了基于Hadoop解决清单交互式分析的思路,交互式分析利最复杂的查询是,所有的数据都不能建索引,不知道要查的数据在哪里,传统的方式只是爆扫,而我们尝试解决这个问题,目前解决的情况给大家交流一下。
TAG: 大数据 华为 多维分析
