大数据时代给传统数据仓库架构带来了一系列的冲击和挑战,仅从源数据采集和存储层面,就让仓储的构建者不得不重新认真地思考:数据在哪里?这个问题的答案改写了企业数据仓库对数据源的既有定义,同时也传递了两方面的焦虑,一是数据规模急速增长,现有的单节点或者共享磁盘架构能否适应海量数据的存储;二是数据结构复杂多样,现有的基于结构化数据为主体的存储方案能否兼容无模式的非结构化数据。
面对企业大数据的挑战,用友华表作为一家提供商业分析产品的供应商,在技术上我们将如何解决大数据的问题呢?目前面对大数据给现有仓库存储架构带来的量的冲击和数据种类增加的挑战,不同的公司会选择不同的技术路线,我们最初试图通过一个大而全的存储架构来解决海量数据和多种数据类型的问题。但结过一段时间反复研究,我们认为大而全的存储架构不是解决大数据的最佳方案,我们目前决定采用的技术路线是让不同种类的数据存储在最适合他们的存储系统里,然后再将不同的数据类型进行融合,企业在融合的数据基础上做商业分析。
本文我将从用友华表的技术思路、存储方案、存储之后的数据如何融合三个层次来阐述我们如何应对大数据的挑战。
分而治之 三面突围
第一,有“容”乃大。“容”,即有足够的容量来存储数据。对于大规模数据,我们将采用分而治之的思想,构建分布式存储系统,并且做到易扩展。保证系统可以方便的增加节点,当企业的数据快速增加时,可以使数据分布始终保持在平衡状态;
第二,有“荣”乃大。即兼用多种存储引擎。大数据因结构复杂多样使得数据仓库要采集的源数据种类无比“繁荣”,因此新的仓储架构也要改变目前以结构化为主体的单一存储方案的现状,针对每种数据的存储特点选择最合适的解决方案:对非结构化数据采用分布式文件系统进行存储,对结构松散无模式的半结构化数据采用面向文档的分布式key/value存储引擎,对海量的结构化数据采用shared-nothing的分布式并行数据库系统存储;
第三,有“融”乃大。如上所述可以兼用多种分布式存储引擎来解决“容”和“荣”的挑战,但企业存储多元化数据的一个重要目标是集成分析,而多种类型数据孤立存储对后续的集成分析会带来极大不便。因此我们还需要构建分布式数据库系统和分布式文件系统之间的连接器,使得非结构化数据在处理成结构化信息后,能方便的和分布式数据库中的关系型数据快速融通,保证大数据分析的敏捷性。
存储方案各不同
上面提到针对大数据规模大、种类多的特点,我们可以采用“容”、“荣”的方案,兼用多种分布式存储引擎分而治之。那么我们就拿非结构化、半结构化和结构化这三大类数据的存储方案分别举例说明,以便让大家更清楚的了解到不同类型的海量数据通常都是通过哪些方式来进行存储的。由于谈到的都是业界普遍使用的开源或商业方案,因此不做深入讨论。
首先,适合存储海量非结构化数据的分布式文件系统。
HDFS(Hadoop Distributed File System),是鼎鼎大名的开源项目Hadoop的家族成员,是谷歌文件系统GFS(Google File System)的开源实现。HDFS将大规模数据分割为多个64兆字节的数据块,存储在多个数据节点组成的分布式集群中,随着数据规模的不断增长,只需要在集群中增加更多的数据节点即可,因此具有很强的可扩展性;同时每个数据块会在不同的节点中存储3个副本,因此具有高容错性;因为数据是分布式存储的,因此可以提供高吞吐量的数据访问能力,在海量数据批处理方面有很强的性能表现。
其次,适合存储海量无模式的半结构化数据的分布式Key/Value存储引擎。
HBase(Hadoop Database),也是开源项目Hadoop的家族成员,是谷歌大表Bigtable的开源实现。HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,它不同于一般的有模式的关系型数据库,HBase存储的数据表是无模式的,特别适合结构复杂多样的半结构化数据存储。此外,HBase利用HDFS作为其文件存储系统,利用MapReduce技术来处理HBase中的海量数据。
第三,适合存储海量结构化数据的分布式并行数据库系统。
Greenplum是基于PostgreSQL开发的一款MPP(海量并行处理)架构的、shared-nothing无共享的分布式并行数据库系统。采用Master/Slave架构,Master只存储元数据,真正的用户数据被散列存储在多台Slave服务器上,并且所有的数据都在其它Slave节点上存有副本,从而提高了系统可用性。
Greenplum最核心的技术就是,大表数据分片存储,可以应对海量数据;基于大表的查询语句在经过Master分析后可以分片发送到Slave节点进行并行运行,所有节点将中间结果返回给Master节点,由Master进行汇总后返回给客户端,大大提高了SQL的运行速度。
“三融合一”——Xnet数据交换网络
各种复杂而大量的数据犹如一张立体的大网,三类数据是网里三种不同的结点,前面提到的三类分布式存储引擎可以将不同的结点有序的安排在网上,并且每种相同的结点都可以直接用线相互连接起来。但此时只是三个孤立的面,就如同三类数据间存在的孤岛。若要把这三个面也相互连接起来,形成一张可以从点到面,从点到点,从面到面的大网,则需要构建一个方便、快速的数据交换组件,它是一个连接器,可以实现“三融合一”,满足大数据存储有“融”乃大的特性。
下面先介绍一下数据交换网络Xnet(Exchange Net)的一些基本构思,它是一个可以完成分布式文件系统和分布式数据库之间海量数据快速交换的组件。
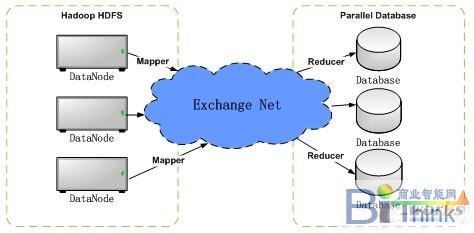
上图仅是一个简化的逻辑图,在实际的物理部署中,HDFS集群和并行数据库集群共用一个服务器集群,即在服务器集群的每个节点上既有HDFS数据节点也有并行数据库的数据库单实例。处于中间融通两方数据的蓝色部分就是我们本节要探讨的分布式、可并行运行的高速连接器Xnet。
