本文在制造业商务智能技术及产品研发的基础上,立足烟草行业,通过将商务智能与云计算结合,将数据挖掘算法应用于云平台,对基于Hadoop的烟草商务智能平台展开研究与设计。
1 K—means算法并行化
烟草企业管理者做出决策是依据从海量业务数据中获取的有用信息,而有用信息的获取则是通过数据挖掘技术。在多年烟草经验指导之下,发现数据挖掘的K—means算法比较符合烟草实际的应用,因此将K—means算法与MapReduce编程模型结合,实现并行处理数据,提高效率。
1.1基于MapReduce的改进K—means算法并行设计
K-means算法是聚类分析的常用算法,算法的特点为对聚类中心和剩余数据对象与聚类中心距离进行迭代计算,直到聚类中心不再变化,即可结束算法,得到最终的聚类结果。由上述可知,K-means算法是通过迭代,不断调整聚类中心,不断对数据进行重新分配的算法。当实际应用中数据量不断增大达到海量级别时,算法运行速率将很难达到应用要求。因此,应用MapReduce编程模型的并行计算方式,将K—means算法并行化,提高算法的运行速率,降低对内存和处理器的要求。
K—means算法的MapReduce并行化分两部分,第一部分的任务为处理数据格式,以行的形式存储数据,使其适合MapReduce编程模型,第二部分并行执行K—means算法。
图1为K—means算法的MapReduce并行化流程图,A部分代表处理数据格式,B部分代表K—means算法的并行实现,A和B两部分都运行有多个Map和一个Reduce。
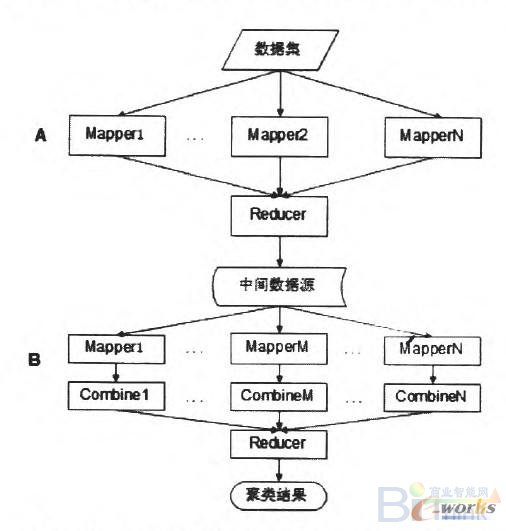
图1 K-means算法的MapReduce并行化流程图
1 2基于MapReduce的K—means算法并行实现
从前面介绍中可知,K—means算法的主要操作就是将数据集中的每个数据对象分配到距离其最近的聚类中心点,并且此操作也是独立运行的,因此将算法的这步做并行实现。并行的整体操作为:先根据K—means算法选取聚类中心,从中存储到HDFS文件中,然后迭代运行Map、Combine、Reduce三个函数,直到聚类中心不再变化,算法收敛。图2为基于MapReduce的K—means算法并行实现流程图:
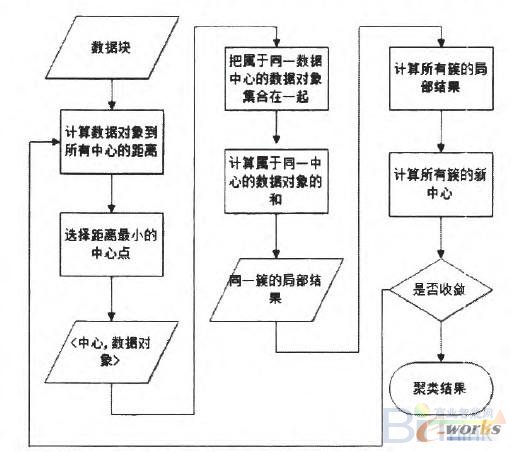
图2基于MapReduce的k-means算法并行实现流程图
2数据仓库设计
数据仓库是企业进行业务数据分析、挖掘有用信息的基础。在本系统中,建立数据仓库是用于为决策分析服务,将企业的数据资源及时转化为决策者需要的信息,并以各种方式展现分析的结果,图3为系统的总体结构图。
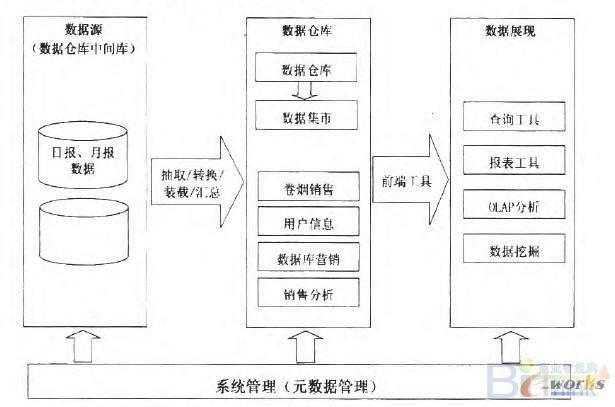
图3系统总体结构图
2.1数据源
商务智能平台是对与企业有关的所有内部和外部的数据进行收集、汇总、过滤、分析、传递、综合利用,其数据源主要集中在企业内部营销系统、ERP系统、RFID卷烟成品数字化仓储系统、一号工程、工商协同及其它外部系统数据,具体如图4所示:
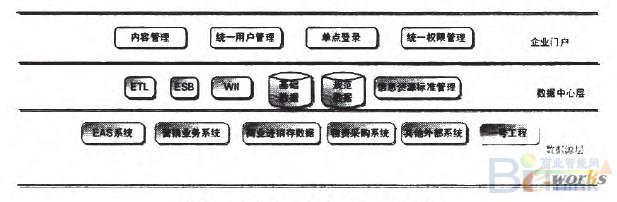
图4商务智能平台数据源
